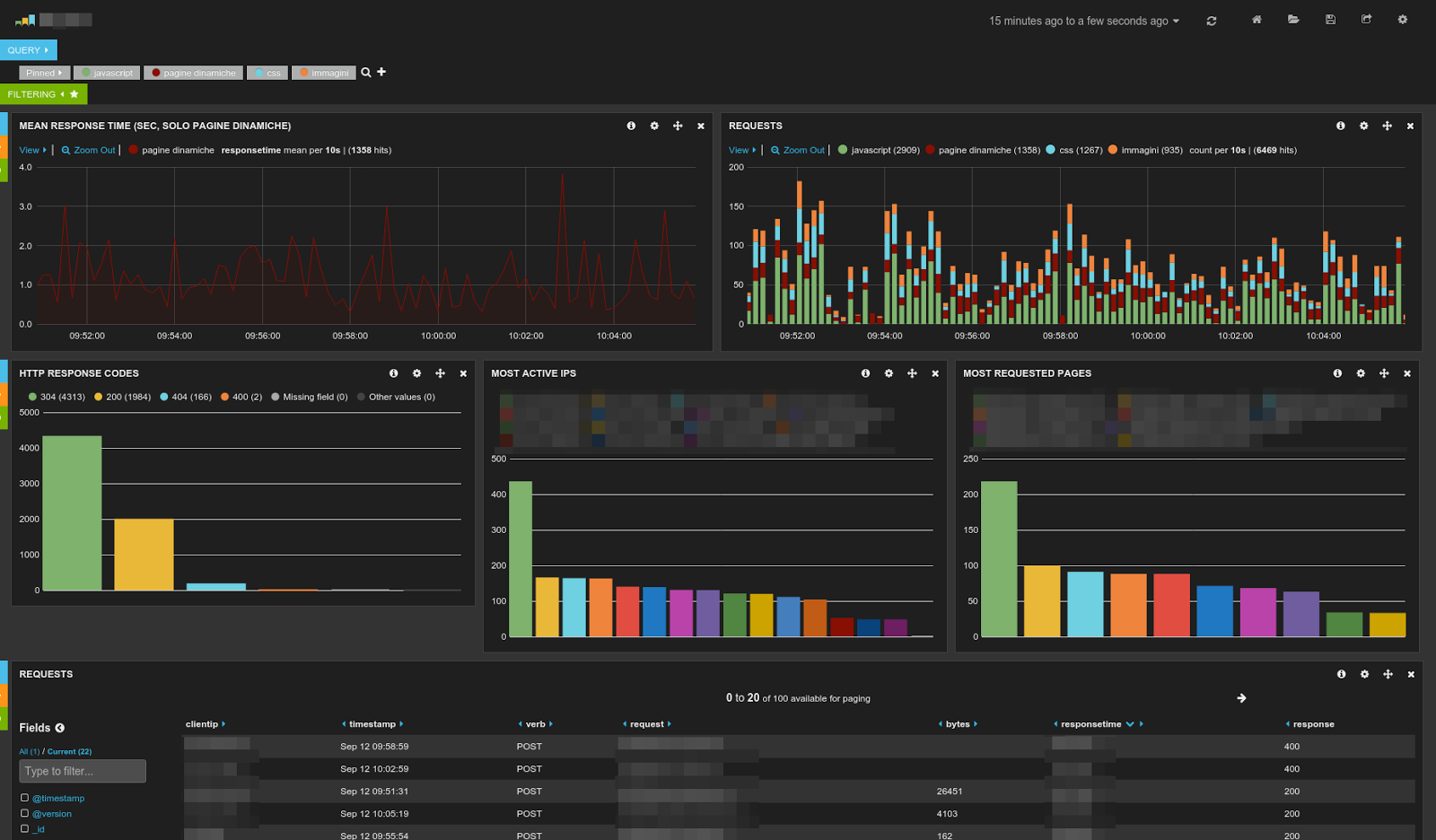
Who said that grepping Apache logs has to be boring? Sample of dashboard that can be created with ELK. Pretty impressive, huh? The truth is that, as Enteprise applications move to the browser too, Apache access logs are a gold mine, it does not matter what your role is: developer, support or sysadmin. If you are not mining them you are most likely missing out a ton of information and, probably, making the wrong decisions. ELK (Elasticsearch, Logstash, Kibana) is a terrific, Open Source stack for visually analyzing Apache (or nginx) logs (but also any other timestamped data).